


Coaches today have access to incredible athlete data—GPS tracking, barbell tracking, heart rate monitoring, etc. But the vast majority of it is useless.
Why? Two reasons:
Humans are not good at interpreting data to make fast, consistent, and accurate decisions.
Half the time, people don't even know what decisions their data should inform.
Nonetheless, coaches continue to obsess over data aggregation tools and charting tools that don't actually do anything. They set up their fancy devices, and they build their fancy charts, and then what? Do athletes magically improve? No. Someone has to decide what to do about the data.
We've already said it before, but we'll say it again here:
Data alone does not lead to better decisions.
Data alone does not lead to better or more efficient execution.
Data alone does not lead to better outcomes.
We demonstrated this in our decision tree webinar with a simple experiment. The host, Ernie Rimer, asked the participants to fill out a poll where they identified the top three training needs for the two athlete profiles below:
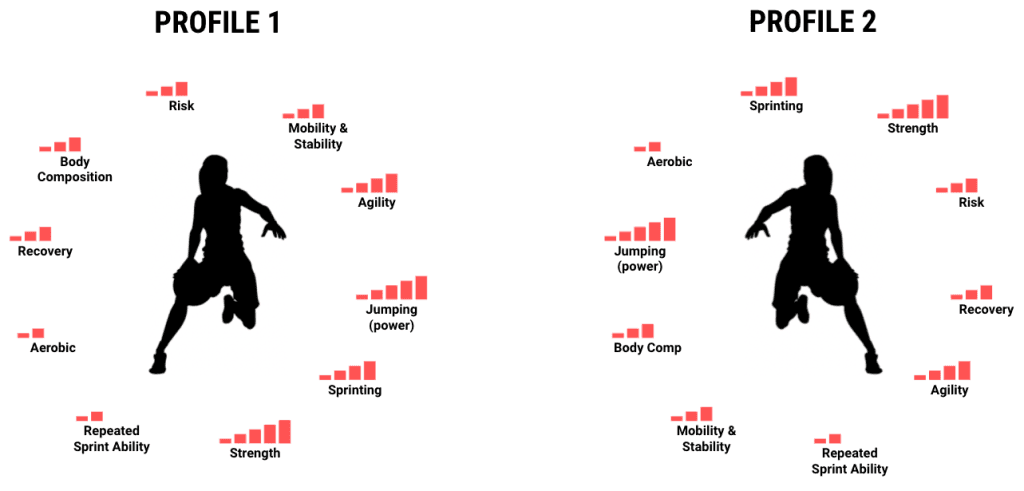
These two athlete profiles are exactly the same (just arranged differently), and they were only shown several minutes apart, but the respondents prioritized completely different needs for each one. Ernie probably could have shown the same profile in the exact same arrangement, and the attendees would still have likely come up with different priorities.
We're not trying to say that data is worthless or that coaches aren't smart enough to interpret data. On the contrary, the profession has thousands of amazing coaches using data, research, and their experience to improve human performance every day.
The point is that humans are limited in their ability to quickly interpret and use data. If we had unlimited time and resources, we could analyze all the data points for all of our athletes and come up with an individualized plan for each one. But that's usually not practical, and that still wouldn't guarantee consistency in how the data is interpreted.
If we want to achieve both procedural consistency (the process of making decisions) and content consistency (the outcomes from our process), we need to codify our thinking. Enter decision trees.
The value of decision trees in high performance sport
A decision tree is a simple tool that helps us clearly define our decision making criteria so that we can consistently apply the same logic to achieve our desired outcomes. In other words, a decision tree helps us be more methodical in our application of sport science.
To use an analogy, consider the maintenance of a race car. The mechanics don't just casually look over a diagnostics output and make a judgment call about what needs to be fixed. Every test and every data point is meant to ensure the proper functioning of specific parts and systems. If a test output is outside the range of acceptable values, the mechanic knows exactly what steps to take. The protocols for addressing a particular test failure are defined in advance.
Our protocols for sports performance should be no different. Whether or not we've written them down yet, we have algorithms that we use to make training decisions for our athletes. But because our brains are subject to biases and distortions, these algorithms are never quite consistent. And because we're not totally consistent, we can't accurately evaluate our effectiveness or trust that we're being scientific.
If we extract these algorithms from our heads and clearly document them, we can systematically execute, evaluate, and continually improve our decision making protocols. If we simply rely on our "experience," we're shooting from the hip. Furthermore, if we don't know what data we're collecting, why we're collecting it, and what we're going to do with it, we're wasting our time.
Data is worthless unless it leads to action. If you can't point to specific training interventions that happen in response to the data you collect, then why are you collecting data? Decision trees are powerful tools to help us bridge the gap between data collection and effective training intervention.
Decision trees are also great for communicating our thinking to others. By helping our colleagues understand the rationale behind our approach, we can get feedback, increase buy-in, improve execution, and ultimately drive better outcomes across the entire team. This also improves the consistency of how our training programs are delivered.
Building a sports performance decision tree
When you go to actually build a decision tree, it doesn't have to be anything fancy or complex. You can start with pen and paper, then formalize it and implement it from there. When all is said and done, good decisions in a sports performance setting can be boiled down to three main ingredients:
Relevant data (inputs)
Clearly defined logic (if this, then that)
Relevant interventions (outputs)
But when you start putting pen to paper, you'll want to begin with outputs, then determine your relevant data points, and build out your logic last.
Start with the outputs
Assuming you've already selected the athletes you want to train and the area of training you want to implement, you'll start your decision tree by laying out the possible interventions. As an example, let's consider a simple strength training scenario. We have a base program that we want our athletes to follow, but we know that there will be circumstances on any given day when their routine should be modified.
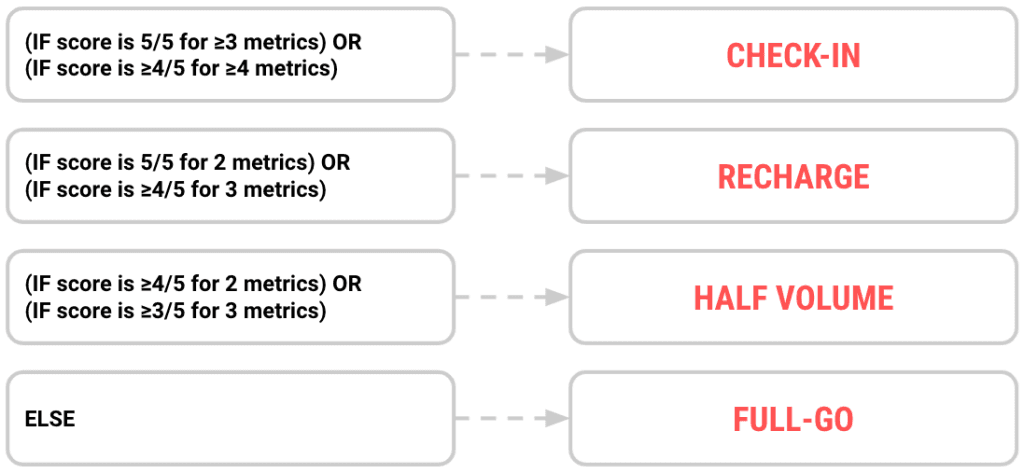
After giving it some thought, we decide that there are four possible variations that we may want to assign: 1) Full-go, where the athlete is cleared to do the program as originally prescribed; 2) Half-volume, where the athlete should do a less intense variation of the day's workout; 3) Recharge, where the athlete should be assigned a low-volume workout to allow for more recovery; and 4) Check-in, where the athlete should consult with a coach before doing any work that day.
Refine the inputs
With the possible outcomes in mind, we need to determine which data points should influence our decisions, and which data points we should ignore. You may be tempted to evaluate as many data points as possible, but that's generally not necessary. In all likelihood, there will only be a few metrics that have the most impact on your decisions, and the marginal benefit of evaluating additional data quickly diminishes. Just use the 80/20 rule as your base heuristic, which states that roughly 80% of consequences come from 20% of the causes.
Continuing with our example, let's assume that we determine that there are five measurements that are most important to our decision: stress, sleep, fatigue, mood, and soreness. We'll measure these by surveying the athletes at the start of each day, and we'll assign them to one of the four interventions listed above depending on their responses.
Fill in the logic
Now that the inputs and outputs are laid out, we're ready to define the criteria that links them together. This is where the rubber meets the road. It forces you to explicitly write out all the implicit logic you've developed from your training and experience. As you go through this exercise, sometimes the logic might not be perfectly clear. That's ok. You might just have to make a judgment call, then refine the logic as you observe the consequences of the decisions over time. The important part is that you document your protocols so that you have a clear set of criteria that you can tweak and experiment with.
To finish out our example, we'll use some simple "if this, then that" logic to evaluate various combinations of our measurement variables, and map them to specific interventions.
To start off, we'll say that if an athlete scores a 5/5 on 3 or more of the metrics OR they score a 4 /5 or higher on 4 or more of the metrics, we want the athlete to check-in with a coach. We can shorten this into a concise logical statement like so: (IF score is 5/5 for ≥3 metrics) OR (IF score is ≥4/5 for ≥4 metrics) => Check-in. Using the same notation for all four branches, we can create a concise decision tree:
For more examples and an in-depth discussion on how to build decision trees in practice, checkout our webinar on this topic.
Implementing decision trees in high performance sport
You might be thinking to yourself, this stuff is all great in theory, but how can I actually use something like this in practice? I can't evaluate the scores of every athlete at the beginning of the workout session and run them through the logic. And you're absolutely right.
Oftentimes we collect data on athletes, but we seldom have the time, tools, or resources to analyze the data and use it to make decisions in real time. What benefit do we get from making athletes fill out wellness questionnaires if the results don't influence training? If an athlete comes in on Monday with high levels of stress and fatigue, but you don't get around to analyzing their response until the day is over, the window of opportunity has already passed. The time to act was right when they took the survey.
We've solved this problem with FYTT, which we'll talk about below, but not all decision trees have to be implemented in real time. You can evaluate things at the end of the week, at the end of the month, or at the end of a cycle. Before you decide on a cadence though, you'll want to establish a data collection protocol.
Establish data collection
Let's suppose we've built a decision tree around sprint profiling that helps us determine whether to focus sprint training on acceleration or top speed. How are we going to get the data that will be evaluated in the decision tree? Most likely we'll use timing gates to capture sprint intervals at various distances. Then we will use those intervals to calculate a force-velocity profile, which gives us the relevant data points to run through our logic.
For every decision tree, we want to have all the elements of our testing protocol clearly laid out. In our sprint profile example, we would specify the intervals at which the timing gates should be placed. We would identify the spreadsheet or software platform used to crunch the numbers and spit out the metrics. Every step of the process should be explicitly outlined so anyone can follow it.
The specifics of data collection will be different for every decision tree. The important part is to make sure that everyone understands the process so that you get consistent and accurate measurements every time. An amazing decision tree is only as good as the inputs—garbage in, garbage out. Make sure that your data collection process is solid.
Establish a cadence for evaluation
With your data collection protocol documented, you're ready to establish a cadence for how often you want to collect data and evaluate it against the decision tree. This determination is usually based on the practicality of collecting data, the length of time needed to execute the interventions, and the stress endured by athletes as a result of the testing process.
If your data collection process takes a lot of time and effort, you'll have to weigh the benefits of testing frequently versus the burden of carrying it out. With the right tools, you can embed testing and data collection right into the training process with minimal interruption to the training program or the coach's workflow.
Cadence is also influenced by the nature of the interventions. If your decision tree results in the assignment of a four-week program, you likely won't be evaluating the decision tree every two weeks. This isn't always the case though. You could have several variations of a ten-week program, and you might evaluate your logic every week to determine which variation of the program athletes should be assigned to that week.
Lastly, you want to consider the impact that the testing process has on your athletes. This usually goes without saying, but the last thing we want is to cause an injury because we're testing maximal effort too frequently. Make sure that the cadence of testing and the execution of interventions is consistent with the principles of proper recovery.
Establish a link between evaluation and execution
Once your decision tree logic is defined, your data collection process is solid, and you have an appropriate cadence, you want to make sure that the decisions actually get carried out. This might seem obvious, but it's possible to lose focus on proper execution if you get lost in the weeds of analysis.
The whole point of building decision trees is to deliver the right training to the right athlete at the right time. So make sure that the proper intervention gets administered once the logic has been evaluated. Whether you have a staff meeting to hand out assignments or some automated system of delivering programs to athletes, just make sure it gets done.
Automating decision trees for maximum impact and efficiency
At the end of the day, we're trying to solve the problem of delivering individualized, science-driven programs to many athletes at once. If we could analyze all the data for every athlete we trained, we could provide the level of individualization that they need. But that's just not the world we live in. We need a way to apply sport science across large groups of athletes in an efficient manner.
Coaches have devised creative ways to solve this problem over the years. Most of the solutions are Excel-based, but if you're really ambitious, you can duct-tape something together that links surveys, databases, and spreadsheets. These systems take a tremendous amount of time to construct, and they are very brittle. But it can be done.
At FYTT, we'd like to think that we've developed the ultimate solution for automated decision making in sports performance management. Our system allows you to build decision logic, collect data, then make automated, real-time adjustments to training interventions (take a tour of the software to see for yourself). Once you set up your logic, you never even have to look at the data. Everything just works, and athletes get the appropriate interventions without anyone analyzing numbers or looking at a chart.
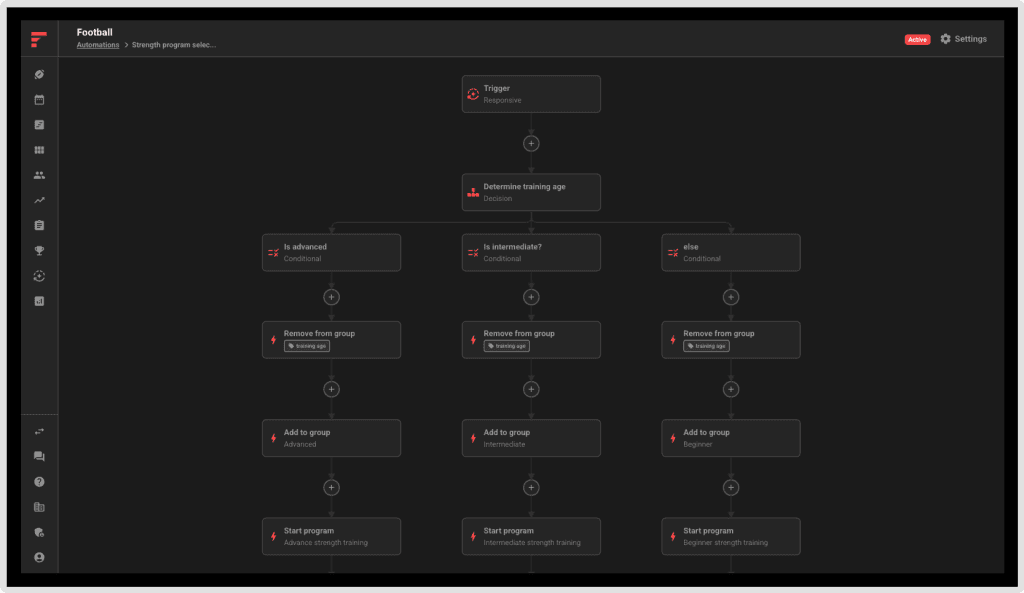
The idea is to create a workflow where building programs, collecting data, and executing data-driven decisions are all part of a seamless process, and to automate as much of it as possible. This will amplify your impact as a coach and allow you to unlock the power of sport science for all your athletes.





